

Build vs Buy IA : pourquoi le build interne coûte 4 à 8 fois plus cher qu'une plateforme dédiée
Uber a brûlé l'intégralité de son budget IA annuel 2026 en 4 mois. La réaction interne, rapportée par TechCrunch, a été un plafond de 1 500 dollars par employé et par mois sur les outils agentiques comme Claude Code. Le COO, Andrew Macdonald, a publiquement reconnu sur le podcast Rapid Response qu'il n'arrivait pas à tracer un lien clair entre la consommation de tokens et la valeur livrée aux utilisateurs.
Quand Uber, qui dépense 3,4 milliards de dollars en R&D et dispose probablement des meilleures équipes d'engineering AI au monde, n'arrive pas à industrialiser son usage de l'IA sans exploser ses coûts, la question se pose pour toute équipe marketing qui envisage de construire son propre outil IA en interne avec Make et ChatGPT.
Le réflexe build en marketing
Pour une équipe marketing enterprise, l'argument du build a une logique évidente.
Les briques sont accessibles. Les API de Claude, GPT et Gemini sont documentées. Make et n8n permettent de chaîner des prompts. Notion ou Airtable servent de base de connaissances. Un développeur freelance ou un ops marketing avec quelques compétences techniques peut assembler un workflow en quelques semaines.
L'argument financier suit. Les licences LLM coûtent 20 dollars par mois. Make démarre à 9 dollars. ChatGPT Enterprise tourne autour de 60 dollars par utilisateur. Comparé à une plateforme dédiée, le calcul de surface penche clairement vers le build.
Sauf que ce calcul ignore six réalités qui rattrapent systématiquement les projets internes.

Coût n°1 : la facture en tokens dérape, comme chez Uber
Uber a encouragé ses équipes à utiliser l'IA autant que possible, a mis en place des leaderboards internes de consommation, et a vu son budget annuel disparaître en 4 mois. Le COO a posé le problème en termes financiers directs. La consommation de tokens augmente. La fonctionnalité livrée n'augmente pas dans les mêmes proportions. La trade-off entre tokens et headcount devient impossible à défendre sans métrique de sortie.
Pour une équipe marketing qui assemble son propre workflow, le mécanisme est identique.
Un article SEO long format de 2 500 mots, généré avec recherche web, plusieurs passes de raffinement, fact-checking et optimisation sémantique, consomme entre 80 000 et 200 000 tokens selon le modèle utilisé. À 15 dollars le million de tokens en sortie sur Claude Sonnet ou GPT-4, un article coûte entre 1 et 5 dollars en API brute. Multiplié par 50 articles par mois, plus les déclinaisons LinkedIn, newsletter, email, on arrive à des factures mensuelles de 3 000 à 8 000 dollars pour une seule équipe.
Et c'est avant la dérive. Anthropic a basculé sa facturation enterprise vers le per-token, OpenAI lance les annonces payantes pour compenser ses coûts d'infrastructure, et les outils agentiques consomment 5 à 20 fois plus de tokens par tâche qu'un prompt simple parce qu'ils planifient, agissent et itèrent en boucle.
Une analyse de Rework reprise par TechCrunch formule le mécanisme clairement. Les prix unitaires des tokens ont baissé de 67% en 2025. Les factures totales augmentent quand même, parce que l'usage croît plus vite que les prix ne baissent.
Coût n°2 : la maintenance permanente d'un produit, pas d'un projet
Le piège classique du build interne, c'est de scoper le projet comme un livrable, alors qu'il s'agit d'un produit en exploitation continue.
Vertesia, qui audite régulièrement les projets de plateformes IA internes, publie une grille d'estimation chiffrée. Un projet initialement budgété à 2,9 millions de dollars finit en moyenne à 10 millions, hors migration et maintenance. Le poste équipe de développement passe de 1,5 à 5-7,5 millions. La sécurité et conformité, sous-estimée à 200 000 dollars, finit entre 500 000 et 1 million.
Pour une équipe marketing, ces chiffres semblent éloignés. Ils ne le sont pas. La version Make + ChatGPT suit la même courbe, à plus petite échelle. Le workflow initial fonctionne. Puis les modèles évoluent (GPT-4 vers GPT-5, Claude 3.5 vers Claude 4), les prompts cassent, les formats de sortie changent, les API ajoutent des paramètres, les guidelines marque évoluent, les régulations européennes imposent de nouvelles vérifications. Chaque évolution est un sprint de réingénierie qu'aucune roadmap marketing n'avait prévu.
Amplience, dans son analyse build-vs-buy de mai 2026, résume le mécanisme. La maintenance des modèles se reproduit à chaque génération de modèle. Et plus le périmètre couvert s'élargit, plus chaque transition demande de tests de non-régression.
Coût n°3 : le time-to-market qu'on n'avait pas anticipé
Les estimations de timeline en build interne sont systématiquement optimistes.
Amplience chiffre la mise en production réelle (pas un démo, un outil utilisé par les équipes business pour publier sur un site commercial) à 3-6 mois minimum pour une équipe non dédiée à 100%. Vertesia constate que les projets estimés à 6 mois en interne prennent en moyenne 24 à 36 mois. Une étude de cas documentée sur un acteur des services financiers : 4 millions de dollars et 12 mois budgétés, 13,5 millions et 3 ans réels, pour un système partiellement fonctionnel.
À l'inverse, les plateformes commerciales dédiées au contenu IA déploient un premier workspace opérationnel en 2 à 4 semaines.
Pour une équipe marketing, cette différence est un écart financier matériel avant qu'une seule pièce de contenu n'ait été produite par le nouveau système. Six mois de build, c'est six mois pendant lesquels les agences continuent de facturer, les cycles de validation restent à 15 jours, et la production reste plafonnée aux capacités humaines de l'équipe.
Coût n°4 : un seul modèle, c'est le pire choix économique
C'est sans doute le point le moins compris des projets internes. Construire un workflow sur un seul LLM, c'est garantir de payer le prix fort sur 90% des tâches.
La logique est mécanique. Un article long format demande un modèle haut de gamme pour la structure et la rédaction (Claude Sonnet 4, GPT-4o). Une réécriture stylistique, une déclinaison LinkedIn ou une traduction se font très bien sur un modèle moyen 10 fois moins cher (Mistral, Gemini Flash, GPT-4 mini). Un fact-checking ou une classification de ton se fait sur un modèle ultra-léger 50 fois moins cher.
MakingSense, dans son analyse de mai 2026, donne l'exemple chiffré. Sur 1 000 documents à traiter, 950 relèvent de règles déterministes ou de tâches simples. 50 demandent un raisonnement profond. Un workflow non orchestré envoie les 1 000 documents au modèle haut de gamme. Un workflow orchestré n'envoie que les 50 cas complexes, et traite les 950 autres en nodes légers. L'économie sur le coût d'inférence est de 95%.
C'est exactement ce que Mark AI fait nativement. Chaque étape d'un workflow est routée vers le modèle le plus adapté en coût et en qualité. Claude pour la structure, GPT pour la créativité, Mistral pour la traduction et le contenu européen, Gemini pour la recherche web, modèles spécialisés pour les visuels (Flux, Recraft, Midjourney). L'équipe marketing ne gère ni les API, ni les changements de pricing, ni les bascules de modèles. La plateforme arbitre.
Un build interne sur Make + ChatGPT ne fait pas cet arbitrage. Il envoie tout au modèle configuré, et paie le prix fort sur chaque appel. Sur 50 000 contenus annuels (articles, posts, emails, déclinaisons confondues), la différence se chiffre en dizaines de milliers d'euros de tokens.
Coût n°5 : la dérive qualité, qu'aucun prompt ne corrige
Un build interne en marketing échoue presque toujours sur le même mur, et ce mur est structurel.
Un prompt ChatGPT ou Claude n'a pas de mémoire persistante. Chaque session repart à zéro. La voix de marque doit être réintroduite à chaque génération, et elle l'est imparfaitement. Sans couche de controle dédiée, rien ne détecte la dérive entre les contenus. Sans contexte spécifique, les modèles convergent vers le centre de leur distribution d'entraînement, soit un ton professionnel mesurément enthousiaste, identique pour toutes les marques qui utilisent les mêmes API.
Le résultat est mesurable. Un workflow Make + ChatGPT produit en semaine 1 des contenus alignés sur le brief. En semaine 3, la qualité dérive. En semaine 6, les contenus ne passent plus la validation sans réécriture humaine substantielle. Les équipes finissent par utiliser le workflow comme un générateur de premier jet à retravailler, et perdent la promesse initiale de productivité.
Une plateforme dédiée résout ce problème par architecture, pas par prompt. Une ligne éditoriale encodée une fois, une base de connaissances ingérée et indexée, une couche contrôle qualité multi-niveaux qui vérifie chaque sortie contre les règles de marque avant qu'un humain ne voie le contenu.
Coût n°6 : la sécurité, la conformité et la dépendance fournisseur
Pour une équipe marketing en grand groupe européen, la dimension sécurité-conformité n'est pas négociable.
Un build interne sur des API US (OpenAI, Anthropic) implique de gérer soi-même l'hébergement des données, le traitement RGPD, l'isolation par workspace, la traçabilité des appels, les revues IT et DSI. Ce qui semble être un projet marketing devient un projet juridique et infrastructure. Dans la banque, l'assurance ou l'énergie, ces revues prennent 6 à 18 mois et sortent régulièrement avec des non-conformités bloquantes.
La sécurité et la conformité d'un build représentent 500 000 à 1 million de dollars annuels en équipe et outillage dédiés.
C'est précisément pour cette raison que Mark AI a fait le choix de l'hébergement France, du SSO, de l'isolation par workspace.
Le tableau comparatif honnête : 4 options, 8 critères
Voici ce que donne la comparaison à plat, sur 36 mois, pour une équipe marketing enterprise produisant environ 50 contenus par mois en 3 langues.
Le constat est net. Le DIY n'est pas le moins cher : il déplace simplement le coût du logiciel vers le temps des équipes et la dette technique. Le build custom n'est défendable que si la production de contenu est un avantage compétitif différenciant, ce qui est rarement le cas en marketing pur.
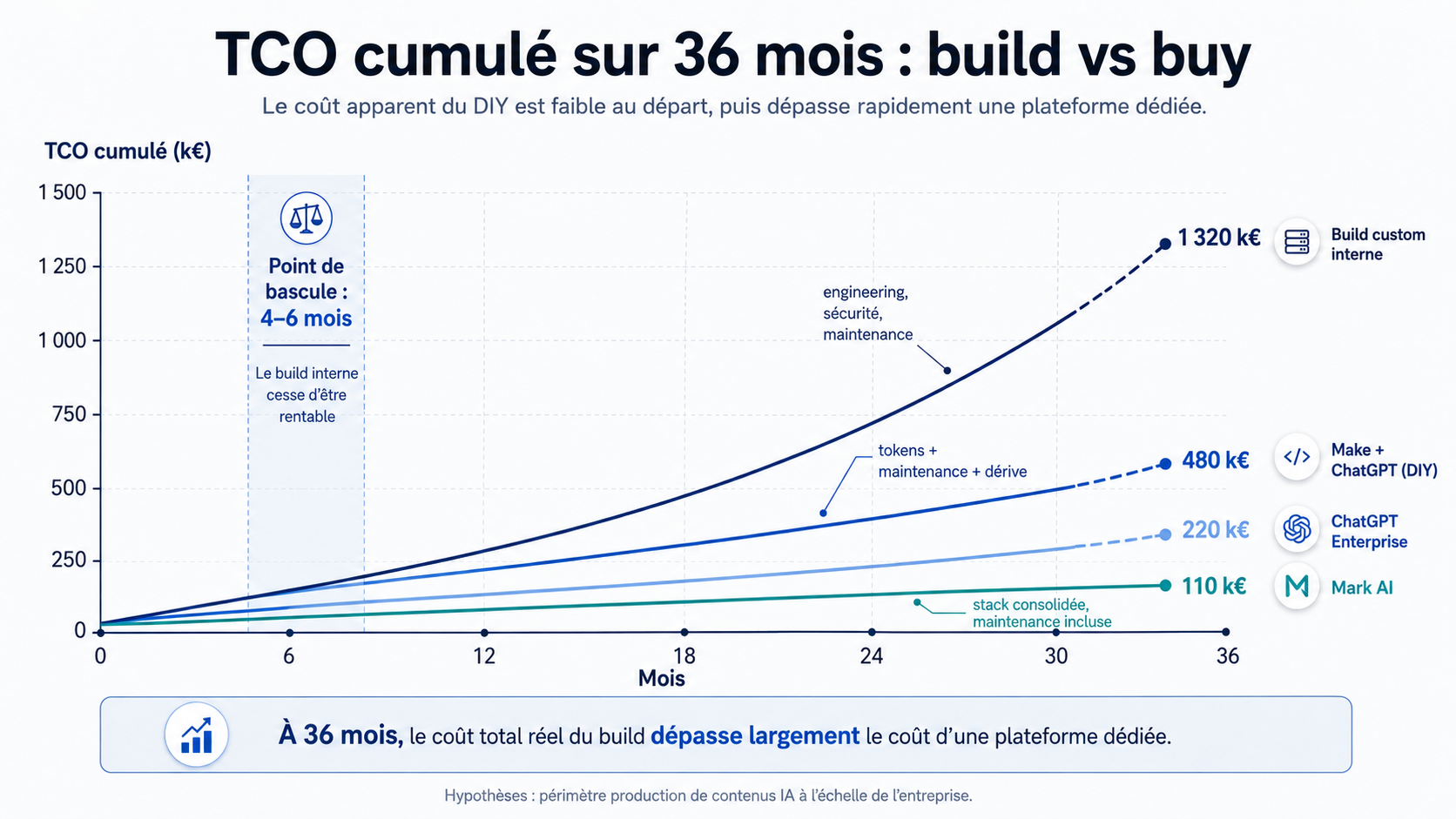
Le calcul honnête : build vs buy à 36 mois
Le bon horizon de comparaison n'est jamais l'année 1. C'est 36 mois, comme le rappelle TechTarget dans son framework de TCO.
Sur l'année 1, le build interne semble compétitif. Quelques licences LLM, un peu de Make, deux semaines d'un développeur, et le workflow tourne. Le coût visible est de 15 000 à 30 000 euros.
Sur 36 mois, le calcul change radicalement. Trois générations de modèles à traverser. Six à dix évolutions majeures d'API. Une revue conformité ou deux à passer. Un ou deux changements de scope (nouvelles langues, nouveaux canaux, nouveaux types de contenus). Le projet interne consolidé arrive entre 250 000 et 600 000 euros sur 3 ans, sans compter le coût d'opportunité de l'équipe engineering détournée d'autres priorités.
Une plateforme comme Mark AI, avec mises à jour, maintenance, sécurité, multi-modèles, connecteurs et CSM inclus. Le break-even arrive entre le 4e et le 6e mois sur la plupart des déploiements observés.
Le ROI ne vient pas de la magie. Il vient de quatre mécaniques précises. La consolidation de stack (4 à 6 licences éliminées). L'arbitrage multi-modèles (économie de 60 à 90% sur les coûts d'inférence à volume égal). L'absence de FTE engineering dédiés. L'absence d'agence sur la déclinaison de contenu.
Ce que ça veut dire en pratique pour une équipe marketing
Il y a un cas où le build interne est défendable. Une équipe avec 100+ ingénieurs disponibles, un cas d'usage propriétaire que rien ne couvre sur le marché, et 24 mois devant elle.
Pour à peu près toutes les autres équipes marketing enterprise, le calcul est tranché. Le build interne sur Make + ChatGPT produit un démo en 15 jours. Il ne produit pas un système de production fiable, gouverné et économiquement soutenable à 36 mois.
La vraie question c'est : combien de tokens, combien d'ETP et combien de mois ai-je à brûler avant que ca fonctionne vraiment.
Uber a payé cette leçon 3,4 milliards de dollars. Une équipe marketing peut la payer entre 250 000 et 600 000 euros, et 12 mois de production perdue. Ou la sauter.
En résumé
Construire son outil IA de contenu en interne paraît rapide et économique. À 36 mois, les six postes de coût (tokens non gouvernés, maintenance permanente, time-to-market, dépendance mono-modèle, dérive qualité, sécurité-conformité) renversent systématiquement le calcul. Le cas Uber, qui a consommé son budget IA annuel en quatre mois, représente la trajectoire par défaut d'un système non orchestré. Une plateforme dédiée comme Mark AI consolide la stack, arbitre entre modèles, et redirige une partie des budgets déjà engagés.
We recommend you


